
皆さんはLLM(大規模言語モデル)を使ったことがありますでしょうか。LLMとは、大量のテキストデータを学習させることで人間と会話しているかのような自然な言語生成、言語理解ができるモデルとなっており、ChatGPTなどが代表例と言えます。
今回はMetaのLLMである「Llama2」を日本語化した「ELYZA-japnese-Llama-2」について詳しく解説していきます。


目次
1章『ELYZA-japnese-Llama-2』の概要・始め方
1-1「ELYZA-japnese-Llama-2」の概要
今世界中で使われているLLMの多くは、英語によって学習が行われたものがほとんどです。これを新たに0から日本語で学習したLLMを作るには、かなりのコストや時間がかかってしまいます。そこで、ELYZAは既存のLLMであるLlama2に新たに日本語のデータを追加で学習することで日本語でのLLMの実現を目指しました。
「ELYZA-japnese-Llama-2」の性能
「ELYZA-japnese-Llama-2」の性能を評価するために、ELYZAにおいて人間によるテストを行いました。
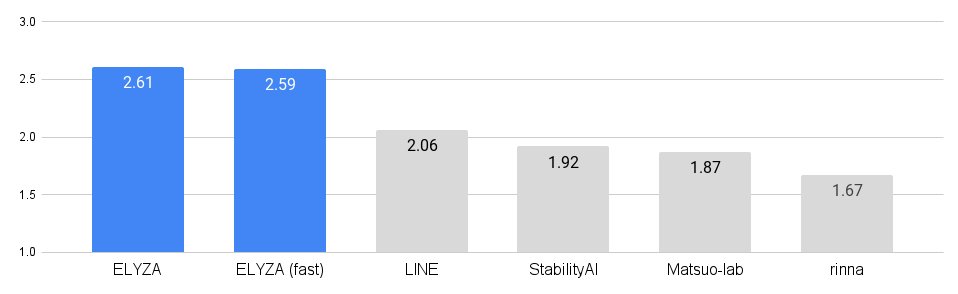
画像出典ELYZA
こちらの画像はELYZAと他の日本語モデルをテストで比較した結果のグラフとなっています。このグラフから分かる通り、日本語モデルの中ではELYZAはトップの性能を誇っていることがわかります。
1-2「ELYZA-japnese-Llama-2」の始め方
「ELYZA-japnese-Llama-2」をを使うには、環境を自分で構築する必要があります。環境構築にはGoogle Colabを使うなどの方法もありますが、今回はMacのローカル環境で行なっていきます。
①モデルのダウンロード
まずは、ELYZAから公開されているモデルをHugging Faceよりダウンロードしましょう。

画像出典Hugging Face
②コマンドの確認
次に、ターミナルアプリを開き必要なコマンドがインストール済みであることを確認します。必要なコマンドは「make」「wget」の2つです。
インストールされているかどうかは、バージョンを確認することで確かめられます。


このように表示されればインストールされていることがわかります。インストールされていない場合はhomebrewのインストールをする必要があります。homebrewをインストールしたら「brew install wget」でwgetをインストールできます。
③llama.cppのダウンロード

「git clone https://github.com/ggerganov/llama.cpp.git cd llama.cpp」というコマンドを入力します。これによってllama.cppがダウンロードできました。
次にカレントディレクトリをllama.cppに移動します。
カレントディレクトリを移動するには、「cd llama.cpp」をコマンドに入力します。
次に「LLAMA_METAL=1 make」を入力します。

これにて「ELYZA-japnese-Llama-2」のセッティングは完了です。

2章『ELYZA-japnese-Llama-2』の使い方
それでは早速「ELYZA-japnese-Llama-2」を実行していきましょう。
文章生成
初めに「ELYZA-japnese-Llama-2」で文章生成をしていきます。
![]()
「./main -m ‘ELYZA-japanese-Llama-2-7b-fast-instruct-q4_K_M.gguf’ -n 256 -p ‘[INST] <<SYS>>あなたは誠実で優秀な日本人のアシスタントです。<</SYS>>木漏れ日をテーマに短い物語を書いてみてください [/INST]’」
プロンプトは上のようになります。木漏れ日という言葉は日本独自のものということを聞いたことがあるので、このようなプロンプトにしてみました。

結果は上の画像のようになります。
「木漏れ日」の意味をしっかりと理解した上で自然な文章が作成できていることが確認できました。
次に、比較対象としてChatGPTに同じプロンプトで文章を生成してもらいます。

画像出典ChatGPT
こちらも「木漏れ日」の使い方としては間違っていませんが日本語の文章の自然さからすると「ELYZA-japnese-Llama-2」の方が自然な文章を作れているように感じますね。
コーディング
次に簡単なコーディングをしていきたいと思います。
「総額と人数を入力することで、一人当たりの支払額がわかる」という単純な割り算を使ったPythonのコードをLlama2とChatGPTに作成してもらい、その違いを確かめていきたいと思います。

画像出典Chat GPT
こちらがChatGPTにプロンプトをした様子になります。簡単なコードの解説とともに、コードを作成してくれました。

次にこちらが「ELYZA-japnese-Llama-2」にプロンプトを作成したようになります。ChatGPTのものと比べるとコードが少し短いような気がしますね。実際に実行して確かめてみましょう。

画像出典Google Colab
しっかりと割り勘の計算ができました。入力の際の「総額を入力してください」などのコメントが設定されているのも使いやすいです。

画像出典 Google colab
「ELYZA-japnese-Llama-2」では関数を定義されただけだったので、自分で関数と引数を打ち込む必要がありました。しかしながら結果自体はしっかりと使える関数を作ってくれたことがわかります。
このようにLLMとして十分に使える性能があり、特に文章生成において優れた能力を発揮していることがわかります。

3章『ELYZA-japnese-Llama-2』の料金・商用利用
3-1「ELYZA-japnese-Llama-2」は商用利用できる?
「ELYZA-japnese-Llama-2」は商用利用をすることができます。Llama2自体が商用利用することができるということで、これをベースとして作られた「ELYZA-japnese-Llama-2」も商用利用ができるそうです。
ライセンスはLlama 2 Community License に準拠しており、Acceptable Use Policy に従う限りにおいては、研究および商業目的での利用が可能です。
実際にELYZAのnoteでは上記のように明記されているので安心して商用利用をできます。
3-2「ELYZA-japnese-Llama-2」は無料で使える?
先ほど使い方をご覧いただいたように、ELYZAからモデルが公開されていることから「ELYZA-japnese-Llama-2」は無料で使うことができます!
しかし、Google Colabを用いて使う場合、容量の問題などで有料プランに入る必要がある可能性もあるのでその際には注意しましょう。
4章まとめ
今回はLlama2に日本語を追加学習させた日本語特化のLLM、「ELYZA-japnese-Llama-2」についてご紹介しました。文章生成においては、他のLLMに比べてより自然な文章を作ることができるのではないでしょうか。

【資料無料ダウンロード】
・AI業務活用お役立ち資料
・用途別のおすすめAIをご紹介
・生成AIの業務導入事例も掲載
関連記事
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。
コメント